Today I wanted to setup my various raspberry pi machines to notify me of their network detail on boot. I have recently purchased a very small 10" 1080p monitor that I can connect to each of the nodes to view boot information.
The motive for this was to see network details after DHCP had completed, and view network information on the boot screen without a login. This would allow me to view details at a glance, and access machines with information directly from the boot screen.
None of the below is possible without heavily leaning on work already done by the amazing Matt Ray (Twitter). He’s done a ton of work around 32-bit ARM builds for Chef and Cinc, and this work is only possible with his lead work.
I’ve recently been tasked with collaborating on a project that involves the deployment of Cumulus Linux to various datacenters, and to facilitate the automation of datacenter setup and deployment.
I’ve been using Chef’s Habitat(tm) and the community distribution “Biome” for a while now. I love the systems, and the community. However, the tools surrounding its usage have not been developed much in the way of graphical systems to aid administration.
Thats all changing!
I’ve worked for a couple of months on a prototype/alpha administrative viewer for the Habitat/Biome.
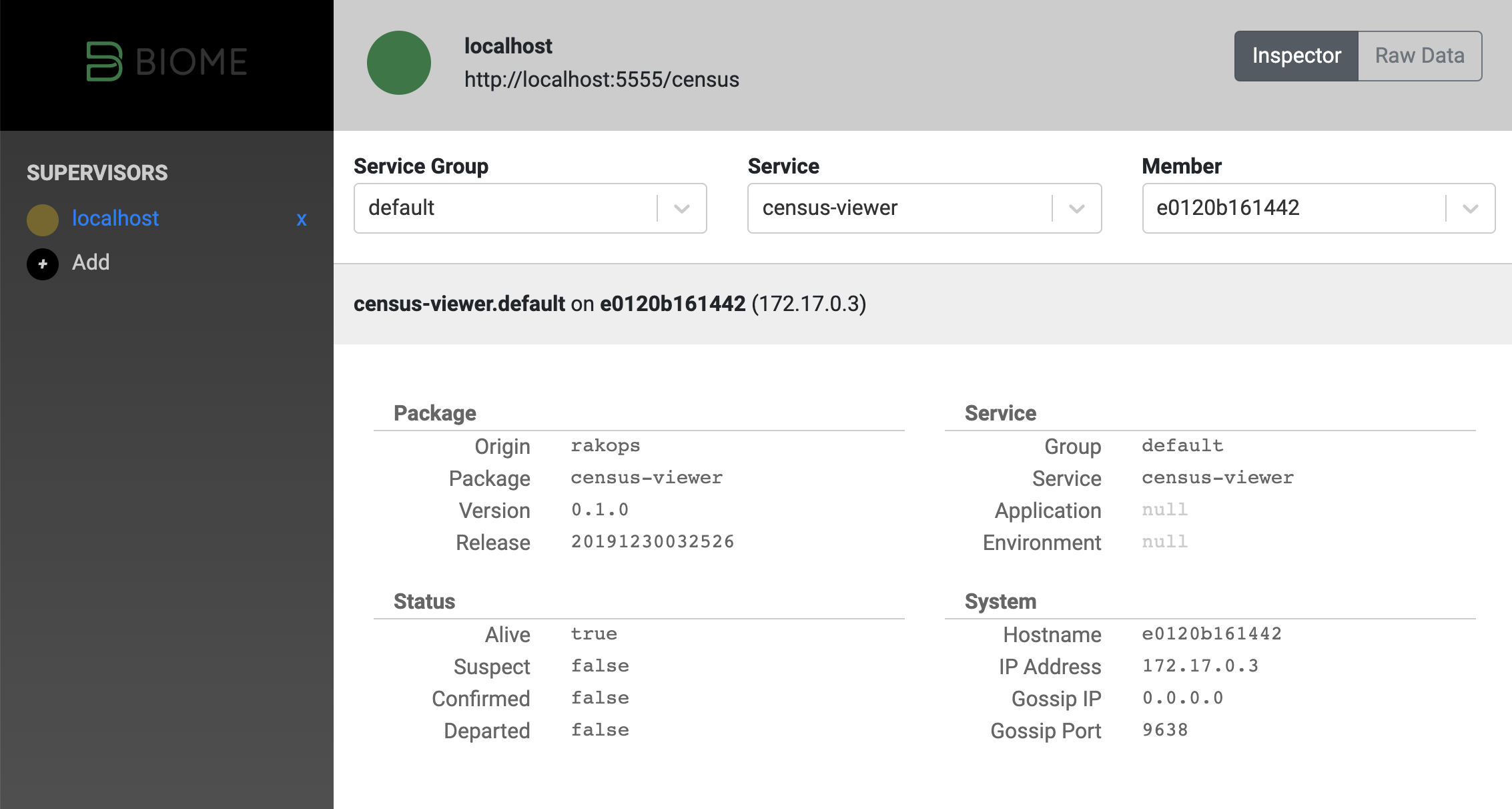
The census viewer comes in 2 parts:
I’ve been doing fairly regular and extensive contributions to the Habitat core-plans repository over the last couple of years. Primarily keeping packages up to date, but also contributing new ones, and helping shape the structure and format of our approach to testing all packages, to ensure quality.
One of the challenges with diverse management of open source software is keeping up to date with changes as they happen. There are a number of projects and sites around that track open source software and can provide notifications, but none offered up-to-the-second source based version information.
Wow! This year during ChefConf 2019 I was awarded as an “Awesome Community Chef” by the Chef community!
For the past 2 years or so, I’ve been putting in a lot of personal time and effort to contribute back to the Habitat project, by way of the central core-plans repository. From here, I’m able to help maintain, update, fix and strengthen software that is used by countless developers and operators around the world.
Nginx is a truly powerful, efficient, configurable web server. I’ve been using it for over 12 years. But for the longest time, I’ve been relying on simple configuration and basic rule sets to get by. While that’s no problem, I wanted to share what I have learned recently with map and geo usage in Nginx configuration.
I feel the Nginx documentation is loosely sufficient, but could do with some more examples.
You’ve got a modern server, its got systemd, journalctl, and you have Habitat supervisor running a Caddy webserver. What an amazing setup of great technology! Gluing these pieces together is easy, but I’ve found a couple of places where I wish documentation had been better. This post serves as a notice to myself and anyone else that is interested in how to get goaccess working in this new modern ecosystem.
There is no completely correct or incorrect way to contribute to open source.
As long as your motivations are in the interest of improving the project, or contributing good resources to the community, I recommend going for it!
Contributions come in all shapes and sizes. Even if you’re fixing a small typo in documentation, or refactoring a large section of code, your contribution is valuable and helpful. Keep that in mind.
Habitat’s core-plans is the central repository for packages/plans maintained by a group of volunteers. These plans form the basis of pretty much everything built with Habitat. From low level libraries and tools such as GCC, glibc, openssl to high level applications like Jenkins, Artifactory, and a whole range of others. The full list can be seen in the Github repository.
Theres a bunch of things that happens behind the scenes of your pull request on the Habitat core-plans repository.
I’ve posted a few times on the topic of Habitat. I feel its the most promising solution for software package management, and deployment available today. If I have managed to help sway you, and thus you’re interested in adopting Habitat, you may find yourself faced with a relatively daunting task.
Migrating a working, functional system from one underlying layer to another is risky, potentially disruptive, and time consuming. All these reasons are why successful financial and enterprise businesses tend to have a slow rate of change.